

Rapidité et sécurité, ça rime avec ? Efficacité. Bien joué, +1. Ça rime aussi avec… PHP ! Pour disposer d’un site dont les pages se chargent vite, tout en offrant un bouclier solide face aux attaques pirates, il existe une…
Dans la vie, c’est fou comme certaines choses peuvent nous faire vriller. Je pense par exemple aux personnes qui doublent éhontément, sans l’air de rien, quand vous faites la queue au supermarché.
À celles qui ne cuisent pas les pâtes al dente, et les coupent au moment de les plonger dans l’eau bouillante (sacrilège). Ou encore à ces réveils très matinaux qui sonnent, sonnent et sonnent encore pour vous tirer d’un lit bien douillet.

Et puis il y a la découverte d’un contenu dupliqué (duplicate content). Vous savez, ce genre de moment très désagréable où vous retrouvez tout ou partie de votre contenu mot pour mot sur un autre site web.
Ou quand ce bon vieux Ctrl+C Ctrl+V (ou Cmd+C Cmd+V pour les pro-Mac) a encore fait des ravages. Comme on dit, ça, ça rend vraiment fou.
Les contenus en doublon sont un vrai problème quand vous les découvrez chez les autres, mais ils peuvent aussi pulluler sur votre propre site WordPress, sans que vous le sachiez vraiment.
Ce qui est tout aussi embêtant, en particulier parce que cela peut engendrer des conséquences néfastes pour votre référencement naturel.
Pour éviter cela, venez, je vous emmène au vent.
Dans cet article, vous allez tout savoir sur ce fichu contenu dupliqué, et surtout des solutions concrètes pour vous en débarrasser. Et promis, c’est garanti sans pétage de plombs.
Sommaire
Qu’est-ce que le contenu dupliqué ?
Le contenu dupliqué (duplicate content, en anglais) désigne un contenu similaire présent sur plusieurs adresses web (URLs) à la fois, que ce soit sur différentes pages d’un même site internet, ou sur d’autres sites.
Cela complique le travail des moteurs de recherche comme Google, qui peuvent choisir de moins bien positionner dans leurs résultats des pages en double.
Afin que cela soit bien clair, et pour schématiser, il y a donc deux grands types de contenus dupliqués :
- les duplications internes, qui ont lieu sur votre site, sans que vous ne le sachiez vraiment, la plupart du temps. Disons qu’elles sont faites à votre insu ;
- les duplications externes, lorsque d’autres sites copient tout ou partie de votre contenu sur leurs pages.
L’image du papier calque
Maintenant, pour imager ce qu’est le contenu dupliqué, faites un bond en arrière de plusieurs (longues) années : direction les bancs de l’école primaire, et la leçon d’arts plastiques.
Vous vous rappelez du fameux papier calque, qui permet de reproduire à l’identique un dessin manuscrit ? Eh bien les contenus en double, c’est un peu ça, en somme.
Disons que le dessin de base représente l’URL originale de votre contenu, par exemple https://votresiteweb.com/votre-super-article/.
Le dessin reproduit à l’identique (ou en partie) à l’aide du calque, illustre quant à lui l’URL dupliquée : https://votresiteweb.com/votre-super-article-bis/.
C’est bon pour vous ? Alors revenez vers le futur, je veux dire dans le présent.

Plus d’un quart du web serait dupliqué
En 2013, Matt Cutts, un ancien ingénieur de chez Google, avait indiqué que 25 % à 30 % du contenu publié sur le web serait dupliqué.
Même si cette statistique remonte un peu, cela permet de vous donner un ordre de grandeur plutôt parlant.
Heureusement, comme l’indique Google, « dans la plupart des cas, ces contenus ne sont pas trompeurs à l’origine ».
Cela signifie que les causes du duplicate content sont bien souvent techniques et non intentionnelles : le webmaster que vous êtes ne fait pas exprès de créer des contenus en double.
Par conséquent, Google, le moteur de recherche ultra-majoritaire en France (plus de 90 % de parts de marché), ne va pas avoir tendance à vous pénaliser si vous n’avez pas pour objectif de « tromper et de manipuler » ses résultats de recherche.
Par contre, attention : si Google ne considère pas cette pratique comme du spam, il n’aime pas vraiment les doublons non plus.
Pourquoi ? Parce qu’au final, il doit faire des efforts supplémentaires pour indexer et « afficher des pages contenant des informations distinctes ».
En référencement naturel, la phase d’indexation correspond au moment où les robots des moteurs de recherche scannent des pages sur l’ensemble du web, afin de les classer dans un index (une sorte de gigantesque base de données).
C’est dans cet index qu’un moteur de recherche comme Google puise pour pouvoir ensuite afficher les résultats les plus pertinents dans ses pages de résultats, appelées SERPs, en anglais.
Comment procède Google face au contenu dupliqué ?
Bon, je vous dis « il » en parlant de Google, mais en fait j’aurais dû dire « les robots de Google », aussi appelés spiders ou Googlebots.
Voici de façon schématique comment ils opèrent, quand ils repèrent des doublons :
- ils parcourent le web à la recherche de nouveaux contenus, en naviguant de liens en liens (rappelez-vous que le web est une gigantesque toile) ;
- lorsqu’ils tombent sur des contenus en double, ils les regroupent dans un « cluster » ;
- puis ils affichent LE meilleur résultat, selon eux, des contenus présents dans ce cluster.

La prime à la popularité, plutôt qu’à l’ancienneté
Le problème, c’est que ce meilleur résultat ne correspond pas toujours au contenu original (celui qui n’est pas dupliqué).
Sur ce point, difficile d’en vouloir à Google : imaginez la difficulté de la tâche pour lui, lorsqu’il doit trouver l’original parmi des milliers de contenus identiques !
Pour procéder, Google ne se base pas sur la date de publication d’un contenu, comme l’indique le spécialiste SEO Daniel Roch dans son ouvrage Optimiser son référencement WordPress.
Ce serait trop simple, puisque vous pouvez « modifier à volonté dans l’administration la date de chacun de vos contenus ».
Google s’appuie donc sur « la popularité de l’URL et du domaine pour déterminer qui est à l’origine du contenu et qui sont les éventuels plagieurs », ajoute Daniel Roch. En d’autres termes, si un site ayant une plus grande popularité vous vole un contenu, c’est vous qui perdez la bataille auprès du moteur de recherche.
Le même Matt Cutts détaille cela dans cette vidéo (en anglais), si cela vous intéresse :
On peut retenir deux choses majeures de cette démonstration :
- Google ne pénalise pas stricto sensu le contenu dupliqué, sauf dans les « rares cas » où il a été créé « dans le but de manipuler nos classements et de tromper nos utilisateurs ». Si cela se produit, le site concerné « ne s’affichera plus dans ses résultats de recherche » ;
- le reste du temps, le contenu dupliqué n’est pas pénalisé, mais c’est tout comme. Si vous êtes victime de duplication de contenu et que Google a décidé de ne pas afficher la version originale de votre contenu, vous devenez invisible dans ses pages de résultats de recherche.
Par conséquent, vos actions de référencement naturel (SEO) peuvent en subir des conséquences importantes.

Quel est l’impact du duplicate content en SEO ?
Le contenu dupliqué peut avoir des retombées négatives sur le SEO (Search Engine Optimization) de vos contenus.
En d’autres termes, vous pourriez voir le trafic diminuer sur votre site, et perdre des positions sur les pages de résultats de recherche pour plusieurs raisons :
- Google ne sachant pas précisément quelle est la version originale d’un contenu dupliqué, il ne va en afficher qu’une, et donc « masquer » tous les autres résultats identiques dans ses résultats de recherche ;
- les liens entrants (backlinks) que d’autres internautes vont faire vers vos contenus dupliqués seront moins efficaces. Les liens seront répartis entre plusieurs publications dupliquées, et auront donc moins de puissance. Or, plus un contenu a de backlinks pertinents, plus il augmente ses chances de mieux se positionner ;
- vous consommerez plus de budget crawl (le nombre de pages maximum que Google peut explorer sur votre site WordPress), car le moteur de recherche va devoir passer plus de temps à explorer votre contenu en double, avec le risque d’indexer moins rapidement de nouveaux contenus « originaux », voire de ne pas les indexer du tout.
Comme le duplicate content se tapit souvent dans l’ombre et ne se laisse pas toujours identifier et apprivoiser, découvrez dans la partie suivante plusieurs moyens pour le démasquer.


Comment trouver et reconnaître du duplicate content ?
Avec vos yeux : la méthode visuelle
Vous les fermez pour dormir, puis les ouvrez grand dès le réveil, et pour lire cet article : vos yeux constituent votre première arme pour déceler d’éventuelles traces de duplicate content, en particulier des duplications externes.
Imaginez : vous avez publié un article, il y a plusieurs mois, qui distille des conseils pour réaliser un succulent brownie au chocolat.
Stupeur, aujourd’hui : vous venez de tomber sur une publication qui reprend mot pour mot plusieurs passages de la source originale. « Hein, mais ça, c’est moi qui l’ai écrit, punaise. Au voleur ! ».
Ben oui, c’est bien vous, et on vous a plagié. Bon, maintenant, tout l’article n’a pas été copié-collé, mais vous vous demandez peut-être si on est dans une situation de contenu dupliqué ? Bien vu.
En la matière, il n’existe pas de règle précise. C’est-à-dire qu’aucun moteur de recherche ne définit une limite à ne pas franchir, du style : « si vous copiez 40 % d’un contenu, vous êtes un méchant duplicateur ! ».
Pour vous aider, disons que si des phrases entières sont copiées – rappelez-vous, Google parle de « blocs de contenu importants » -, vous pouvez considérer qu’un contenu est dupliqué.
Vous n’avez plus que vos yeux pour pleurer, mais sachez qu’il existe aussi des recours possibles, pour sécher vos larmes. J’y reviendrai un peu plus tard dans cet article.
Après les yeux, place à une deuxième arme à votre disposition : un outil pour détecter le contenu dupliqué.
Avec un outil dédié : la méthode tierce
Il existe plusieurs solutions sur le marché pour déceler des duplications internes et externes. Présentation.
Kill Duplicate

Kill Duplicate est un outil premium incontournable qui permet d’identifier des duplications externes, notamment en scannant vos contenus.
Complet, ce dernier permet aussi de traiter le plagiat en vous proposant des solutions directement sur votre tableau de bord (ex : contacter l’hébergeur, le site ou déposer une plainte).
Prix : à partir de 19 € HT/mois.
Copyscape

Copyscape est une solution freemium qui vous aide à trouver des copies de votre page sur le web. Pour vous en servir, il suffit d’entrer l’URL de votre choix dans la barre de recherche.
Croisez ensuite les doigts pour que personne ne vous ait copié. 😉
Vous pouvez ensuite consulter quelles publications Copyscape a identifiées, pour vous rendre compte si le contenu semble dupliqué ou non.
Copyscape est aussi disponible en version premium avec des fonctionnalités beaucoup plus avancées (à partir de 3 centimes de $ par recherche).
DupliChecker

DupliChecker se présente comme un « logiciel anti-plagiat ». Limité à 1 000 mots par recherche dans sa version gratuite, il permet de vérifier l’originalité d’un texte en entrant son URL, un morceau de texte, ou en téléchargeant un fichier.
Vous pouvez donc vous en servir avant et après la publication d’un contenu. Si on peut regretter la présence de nombreuses pubs, DupliChecker reste intéressant car il affiche plusieurs résultats en vous présentant à chaque fois un taux de similarité :
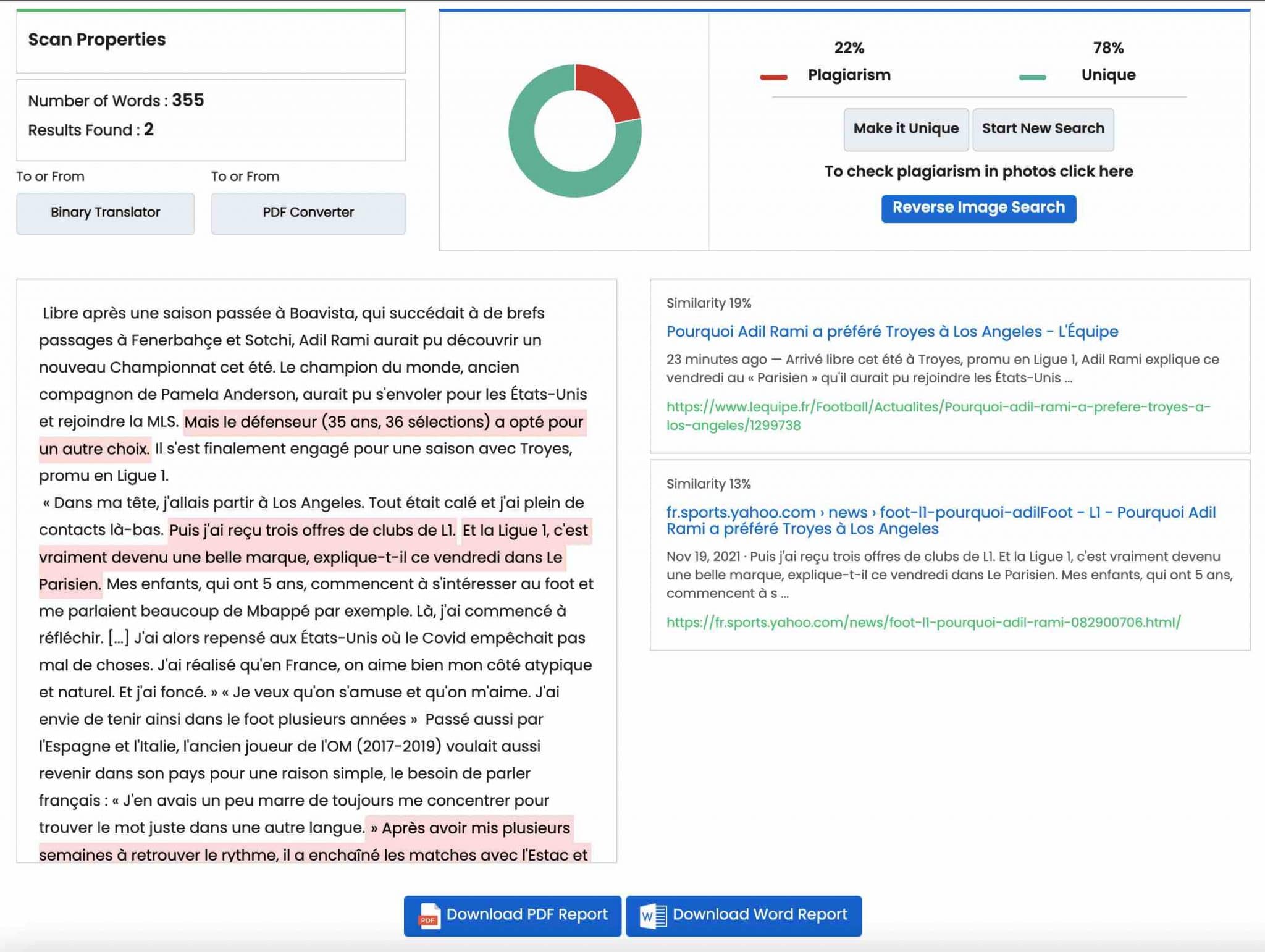
Une version Pro est aussi disponible à partir de 10 $ (environ 9 €), pour un usage jusqu’à 30 000 mots.
Siteliner

Siteliner sera parfait pour « explorer votre site », tel qu’il se présente, c’est-à-dire pour identifier des duplications internes.
Il présente ses résultats sous forme de graphiques. Sa version gratuite permet de scanner un site une fois tous les 30 jours, dans la limite de 250 pages.
Avec l’offre Pro, vous pouvez traiter jusqu’à 25 000 pages, et choisir celles que vous souhaitez exclure du processus d’identification.
Screaming Frog

Screaming Frog n’est pas un outil spécifiquement dédié à identifier du contenu dupliqué. Mais il reste pertinent pour trouver des duplications internes.
Il s’agit d’un crawler, soit un outil d’analyse de votre SEO on-page : il extrait et parcourt les URLs de votre site à la recherche de problèmes (ex : liens brisés, analyse de balises title et meta description, erreurs serveur etc.).
Il saura donc vous renseigner sur certains éléments dupliqués comme les titres h1 et les balises title et meta description de vos pages.
Vous pouvez analyser jusqu’à 500 URLs avec la version gratuite. La version Pro est facturée 185 €/an.
Google Search Console
On termine cette liste d’outils avec un couteau-suisse incontournable : la Google Search Console.
Cet outil gratuit permet de mieux gérer votre site et de suivre votre référencement. Il fournit tout un tas d’infos : erreurs sur votre site, analyse de la recherche, liens, état de l’indexation, erreurs d’exploration etc.
Contrairement à ses petits camarades sus-cités, la Google Search Console ne sera pas en mesure de vous indiquer quelles URLs ont été dupliquées en interne.
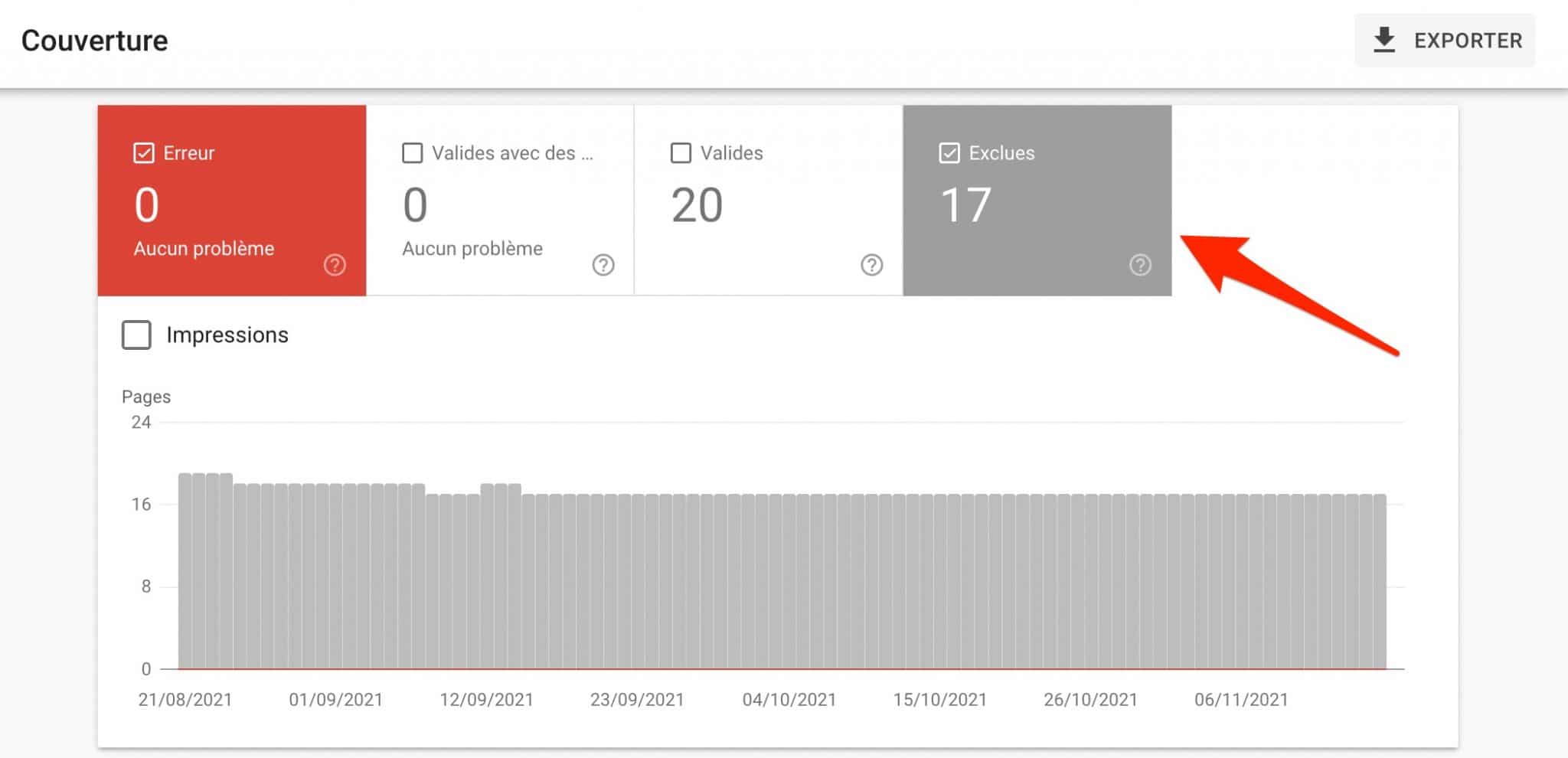
Par contre, elle peut vous aider à le savoir. Pour cela, il vous suffit de vous rendre dans le menu Index > Couverture. Vous pouvez :
- contrôler le nombre d’URLs indexées. Si vous savez que vous avez créé 206 pages sur votre site, et que Google en a indexé 674, vous savez qu’il y a sûrement du contenu dupliqué qui traîne… ;
- vérifier les URLs exclues, pour savoir si elles peuvent entrer dans la case contenu dupliqué.
Notez aussi que bon nombre d’outils SEO comme Semrush ou Ahrefs, pour ne citer qu’eux, disposent aussi de fonctionnalités pour vous aider à identifier du contenu dupliqué sur votre site.
Avec une commande spécifique de Google : la méthode manuelle
Après cette salve d’outils, place à un ultime levier que vous pouvez activer pour trouver du contenu dupliqué : Google.
Pour cela, le célèbre moteur de recherche propose des opérateurs, c’est-à-dire des commandes que vous pouvez lui spécifier dans sa barre de recherche pour filtrer plus précisément ses résultats.
Certaines peuvent être efficaces pour faire la chasse au contenu dupliqué, comme l’opérateur de recherche de site (site:). Pour rechercher une éventuelle duplication externe, excluez votre nom de domaine des résultats de recherche en tapant la requête suivante :
-site:votrenomdomaine.com "titre de votre publication". Ce qui donnerait, dans l’exemple de l’article suivant de WPMarmite : -site:wpmarmite.com “test de 6 plugins SEO incontournables sur WordPress”

Eh bien, c’est un gros morceau que vous venez d’avaler. À présent, vous savez ce qu’est le contenu dupliqué et comment l’identifier.
Reste à en venir à bout et à vous en débarrasser. La suite de cet article va se concentrer sur le mode d’emploi détaillé pour mettre fin :
- aux duplications internes ;
- aux duplications externes.
Je vous propose de commencer par d’éventuels soucis rencontrés sur votre site WordPress.
Quelles sont les causes du contenu dupliqué interne sur WordPress (et comment le résoudre) ?
Les URLs
Une URL correspond à l’adresse d’une page web. Par exemple, la page d’accueil de WPMarmite est accessible sur l’URL suivante : https://wpmarmite.com/.
Vous vous en doutez, plus votre site WordPress comportera de contenu, plus vous aurez d’URLs. Dans le cas d’un gros site e-commerce, par exemple, vous pouvez très vite atteindre les milliers d’URLs, si vous commercialisez beaucoup de produits.
Jusqu’ici, tout va bien. Cependant, nos fameuses URLs vont commencer à vous enquiquiner la vie dans certains cas de figure :
- lorsqu’elles contiennent des indications pour suivre (tracker) les visites sur une page précise. De nouveaux paramètres s’ajoutent alors automatiquement à la fin de vos URLs. L’URL initiale sera par exemple
https://votrearticle.fr, et l’URL dupliquéehttps://votrearticle.fr?utm_source=facebook. Vous ne verrez pas forcément la différence, mais un moteur de recherche si 😉 ; - lorsqu’elles contiennent des paramètres pour filtrer la navigation. C’est souvent le cas sur les boutiques WooCommerce qui utilisent la recherche à facettes. C’est très pratique pour l’utilisateur, qui peut trier des produits par taille, couleur, prix etc. Le souci, c’est que cela crée de nombreuses pages en doublon, avec du contenu quasi-identique mot pour mot, regardez :
https://votreboutique.fr/pantalon-noir-taille-m;https://votreboutique.fr/pantalon-noir-taille-l;
- lorsqu’elles font un usage non différencié des slashs. Par exemple :
https://votreboutique.fr/pantalon-noir-taille-methttps://votreboutique.fr/pantalon-noir-taille-l/sont considérées comme deux URLs différentes par Google, ce qui constitue donc du contenu dupliqué.
Comment résoudre les problèmes d’URLs dupliquées ?
La façon la plus simple de régler un problème d’URL en doublon est d’effectuer ce que l’on appelle une redirection 301.
Une redirection permet de rediriger automatiquement un visiteur souhaitant accéder à une URL A (ex : https://monsupersite.fr), vers une URL B (ex : https://monsitegenial.fr).
Vous pouvez faire ça facilement à l’aide de l’extension Redirection. Alex vous montre notamment comment l’utiliser dans cette vidéo :
Plutôt que de bloquer l’accès des robots d’exploration au contenu en double de votre site web, à l’aide d’un fichier robots.txt, par exemple, Google précise aussi que vous pouvez utiliser ce que l’on appelle une URL canonique.
Grâce à l’usage d’un attribut spécifique dans votre URL, vous indiquez aux moteurs de recherche quelle est la version originale d’une page dupliquée.
Ainsi, vous vous assurez que c’est cette version originale qui sera prise en compte pour un affichage dans les pages de résultats (plutôt qu’une version dupliquée).
Pour info, une URL canonique utilise un petit morceau de code HTML supplémentaire, appelé rel="canonical". Cela se présente de la sorte, en pratique :
<link rel="canonical" href="https://wpmarmite.com/astra/" />
Si vous vous servez de l’extension Yoast SEO, vous pouvez renseigner une URL canonique via l’interface d’édition de l’extension :
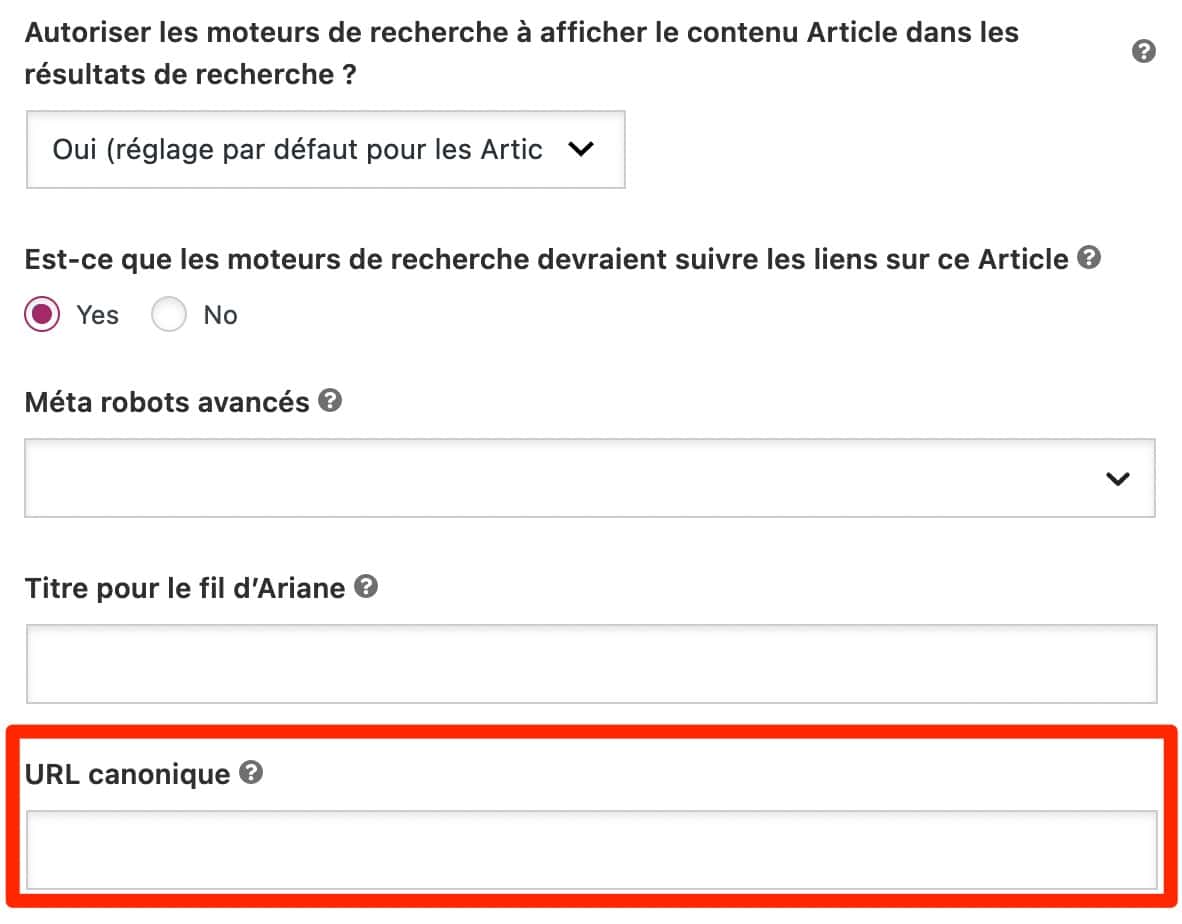
Notez bien que par défaut, Yoast SEO ajoute l’URL de la publication en tant qu’URL canonique. Vous n’aurez donc rien à faire dans la majorité des cas.
Pour apprendre à paramétrer comme un as Yoast SEO, direction notre guide dédié sur le sujet !
La pagination des commentaires
Après les URLs, place à une deuxième cause de contenu dupliqué sur WordPress : la pagination des commentaires.
WordPress permet de diviser en plusieurs pages les commentaires déposés par vos lecteurs sur un article.
Sur le papier, cela semble pratique pour les sites/blogs contenant de très nombreux commentaires.
Le lecteur peut d’abord consulter les plus récents, puis choisir de lire les commentaires plus anciens en se rendant sur une autre page.
C’est là où le bât blesse. De nouvelles URLs vont automatiquement être créées pour chaque page, avec à chaque fois le contenu de votre article.
Comment résoudre le problème de pagination des commentaires ?
La mesure principale que vous pouvez prendre est tout simplement de ne pas activer cette option.
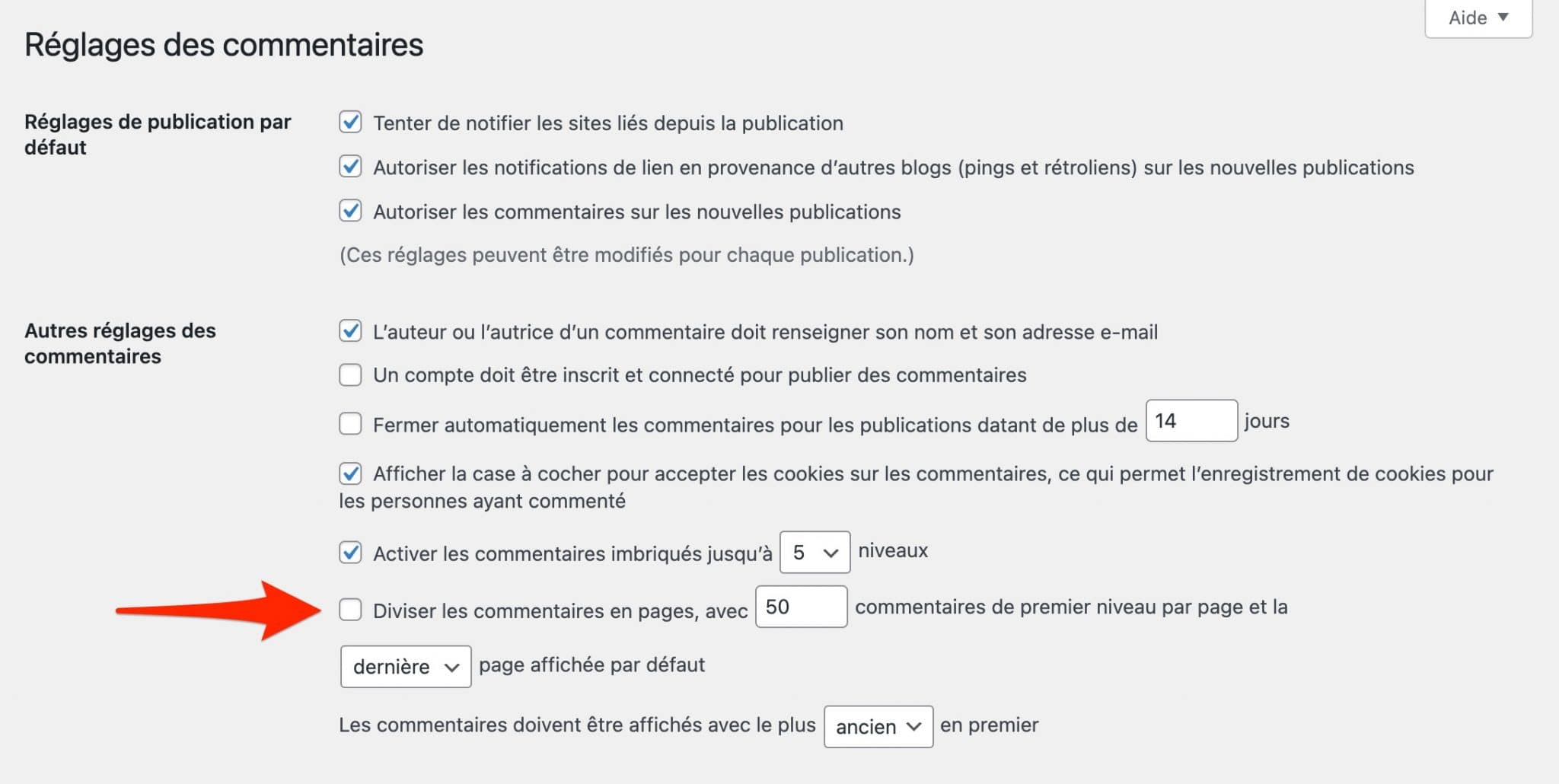
Par défaut, elle ne sera pas cochée lorsque vous installerez WordPress. Je vous invite tout de même à le vérifier en vous rendant dans le menu suivant : Réglages > Commentaires.
Assurez-vous que la case « Diviser les commentaires en pages, avec 50 commentaires de premier niveau par page et la dernière page affichée par défaut » soit décochée.
Les étiquettes
Puisque vous vous trouvez sur l’interface d’administration de WordPress, restez-y, bien au chaud.
Parlons à présent des étiquettes (tags, en aglais), qui permettent de classer vos articles (un peu comme vos catégories, sauf que les étiquettes sont facultatives).
Là encore, l’intention de base est bonne, si l’on se place du point de vue de l’utilisateur. Une étiquette va lui permettre de consulter tous vos articles en lien avec un sujet précis (ex : le cinéma).
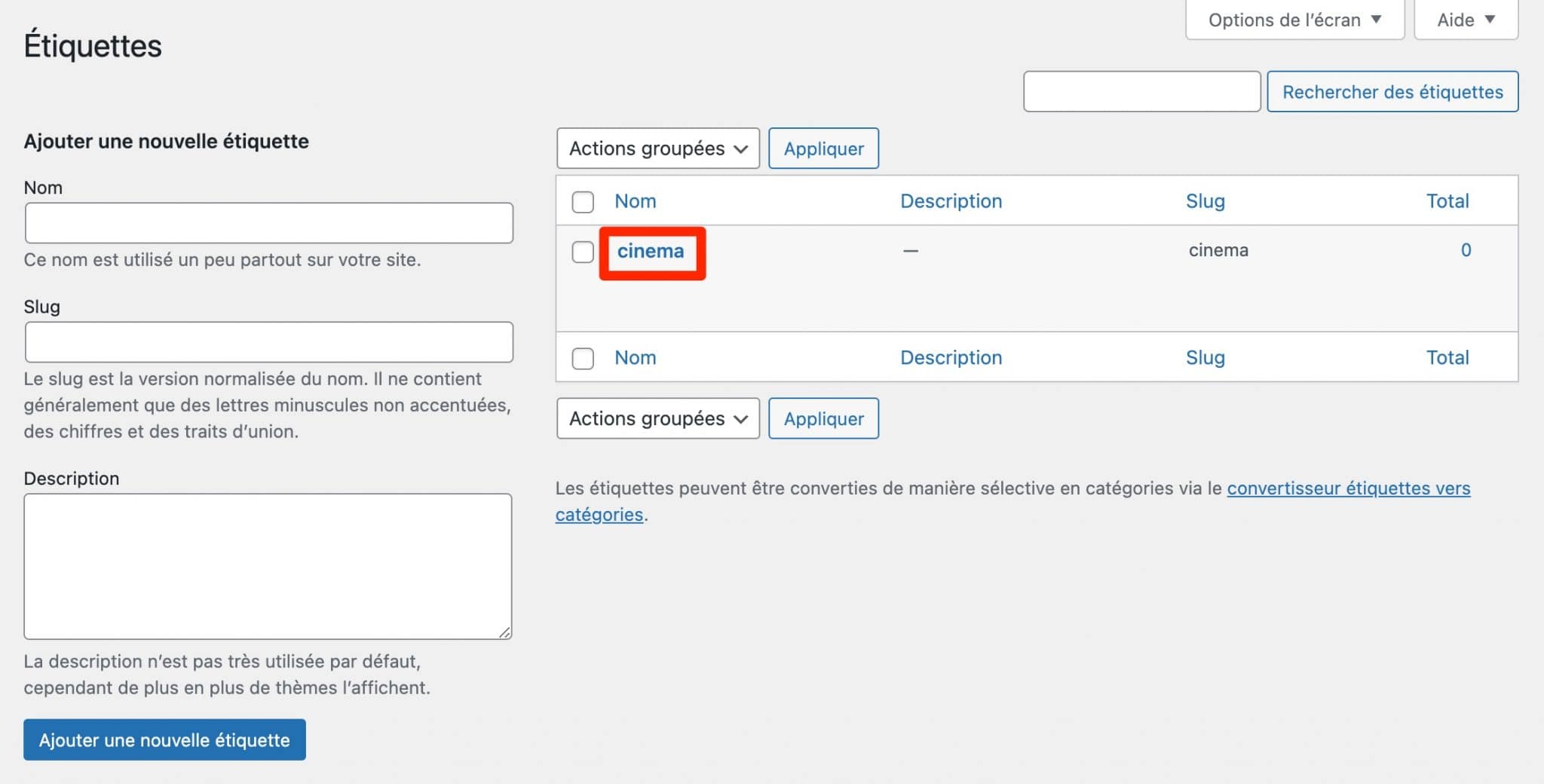
Pour votre SEO, c’est beaucoup plus embêtant, puisque WordPress génère de nouvelles pages d’archives pour chaque étiquette, ce qui signifie que votre article va se retrouver sur des pages supplémentaires.
En d’autres termes, si vous créez 10 étiquettes pour un même article, vous vous retrouverez avec 10 articles dupliqués…
Comment empêcher la duplication des catégories ?
La solution idoine consiste à ne pas utiliser d’étiquettes. Si vous y tenez vraiment, réfléchissez bien, au vu des conséquences que cela peut engendrer.
Et pour tout savoir sur la gestion des catégories et des étiquettes, suivez la formation WordPress de WPChef. ⬇️


Les variantes du nom de domaine
Enfin, il est aussi possible que votre nom de domaine soit accessible sous plusieurs variantes (HTTPS, HTTP, www et sans www) :
https://example.com;https://www.example.com;http://example.com;http://www.example.com.
Conséquence ? Votre site sera accessible de plusieurs façons, ou dit autrement, il sera dupliqué 4 fois.
Cela peut par exemple arriver si vous venez de le passer en HTTPS, sans avoir redirigé la version en HTTP.
Pour savoir si ce cas de figure se présente chez vous, entrez manuellement chaque variante de votre nom de domaine dans votre navigateur favori.
Si aucune redirection ne s’opère vers la version accessible de votre site (ex : celle en HTTPS), vous allez devoir vous mettre au boulot.

Comment définir une seule variante pour votre nom de domaine ?
Jusqu’au passage à la nouvelle Google Search Console, en 2019, il était possible de sélectionner un domaine favori sur l’outil gratuit de Google.
À présent, le plus simple est d’effectuer une redirection 301. Pour cela, vous pouvez par exemple vous servir de votre interface cPanel, si votre hébergeur en fait usage. Découvrez notre mode d’emploi détaillé sur le sujet.
En parlant de nom de domaine, je ne peux que vous recommander la lecture de notre guide complet pour le choisir dans les règles de l’art.
Eh bien, pour la duplication interne, on va dire qu’on n’est pas trop mal. Désormais, place aux mesures à appliquer si jamais vous devez faire face à du contenu dupliqué externe.
Vous allez voir, on va sortir l’artillerie lourde !
3 étapes pour se débarrasser d’un contenu dupliqué externe
Alerte rouge. Vous en êtes certain, votre contenu a été dupliqué. Passée la phase des noms d’oiseaux proférés à l’encontre de l’impétueux site fautif, place à l’action.
Dans ce cas, vous faites quoi ? Vous hurlez votre rage ? Vous appelez la police ou les pompiers ? Vous contactez la DGSI, voire le FBI, si le plagieur est américain ?
Contentez-vous plutôt de respirer un bon coup, puis suivez pas à pas les étapes ci-dessous, qui devraient résoudre votre problème.
Étape 1 : Contacter le propriétaire du site
Avant d’employer la méthode forte, je vous propose d’y aller mollo. Essayez d’abord de trouver une issue pacifique à ce souci ennuyeux de duplicate content.
Premièrement, commencez par contacter le propriétaire du contenu qui vous incommode pour voir ce qu’il en est.
Vous pouvez trouver des informations sur son identité et la façon de le contacter à différents endroits :
- sur la page Contact de son site ;
- sur la page Mentions légales ;
- sur l’encart « Auteur » à la fin de ses publications ;
- sur ses réseaux sociaux ;
- sur votre moteur de recherche favori. Tapez par exemple le nom et prénom de la personne pour voir ce qu’il en retourne ;
- sur la base de données des noms de domaine, le WHOIS.
Whois vous donne des infos sur le titulaire et l’hébergeur, ainsi que des détails techniques. Pour les extensions de noms de domaine en .fr notamment, passez par ici. Vous pouvez aussi faire des recherches de domaines Whois avec Gandi et Who.is.

Après enquête, vous avez trouvé un e-mail ? Il est temps de rédiger votre plus beau message, poli et ferme à la fois, qui détaille la situation.
Expliquez à la personne que vous avez constaté une duplication de votre contenu, pourquoi pas en y ajoutant des captures d’écran et autres preuves tangibles.
Poursuivez en indiquant que cela constitue une infraction au droit d’auteur (personne n’a le droit de reproduire ou de diffuser un contenu sans autorisation). Terminez en demandant à la personne de supprimer le contenu plagié.
Vous avez fait chou blanc, malgré tous vos efforts ? Passez à l’étape 2.
Étape 2 : Se mettre en relation avec l’hébergeur du plagieur
Alors comme ça, la personne que vous avez identifiée comme fautive ne veut pas fléchir ? Contacter son hébergeur va peut-être la faire fléchir. 😉
Pour ce faire, vous disposez de plusieurs options :
- les coordonnées de l’hébergeur doivent normalement figurer sur une page Mentions légales, sur le site de la personne qui a dupliqué votre contenu ;
- sinon, vous les trouverez grâce au Whois.
Lorsque vous avez mis la main sur l’info que vous recherchiez, envoyez le même type d’e-mail déjà rédigé à l’étape 1, en l’adaptant juste à votre destinataire.
Les hébergeurs sont généralement assez sensibles au contenu dupliqué, et devraient vous aider. Ce problème est arrivé à plusieurs reprises à WPMarmite, et cela a permis à Alex de faire supprimer des articles copiés-collés. 😉
Si vous n’avez toujours pas obtenu gain de cause, il est temps de passer à la méthode forte : découvrez-la dans l’étape 3.
Étape 3 : Signaler la page à Google
Sortez la dernière carte de votre jeu, à utiliser en ultime recours : le signalement à Google.
Pour demander à Google de supprimer de ses résultats de recherche « la page qui porte atteinte à vos droits d’auteur », le célèbre moteur de recherche indique qu’il faut lui envoyer une demande DMCA (Digital Millennium Copyright Act).
Pour info, il s’agit d’une loi américaine dont l’objectif est de lutter contre les violations du droit d’auteur.
Dans le détail, voici comment procéder, dans l’ordre :
- rendez-vous sur cette page, et choisissez le service Google concerné (normalement, ce sera « Recherche Google ») ;
- cochez la case « Problème de propriété intellectuelle » ;
- sélectionnez « Atteinte aux droits d’auteur » ;
- cochez « Oui, je suis le titulaire des droits d’auteur ou je suis autorisé à agir au nom du titulaire d’un droit exclusif auquel j’estime qu’il a été porté atteinte » ;
- choisissez « autre », lorsque l’on vous demande le type de contenu mis en cause ;
- cliquez sur le bouton bleu « Créer une demande » ;
- compléter le formulaire, datez, signez et envoyez-le.

Vous l’avez vu tout au long de ces lignes, vous devrez tôt ou tard faire face à du contenu dupliqué, qu’il soit interne ou externe.
Si Google ne pénalise pas directement cette pratique, le duplicate content peut avoir des conséquences néfastes pour votre stratégie de référencement naturel, avec à la clé, une baisse de trafic et de vos positions dans les pages de résultats des moteurs de recherche.
Pour prendre le problème à bras le corps, cet article vous a détaillé comment vous débarrasser de ce fléau de façon concrète, à l’aide d’outils et de bonnes pratiques.
Note : si le référencement naturel vous intéresse, découvrez le programme Enfin visible grâce au référencement de WPMarmite.
De votre côté, comment avez-vous l’habitude de traiter vos contenus en doublon ? Partagez-nous vos astuces et autres retours d’expérience en publiant un commentaire.

Recevez gratuitement les prochains articles et accédez à des ressources exclusives. Plus de 20000 personnes l'ont fait, pourquoi pas vous ?
Je m'inscris




Bonjour, j’ai lu avec intérêt votre article. Il y a quelques années (3 ou 4 ans) j’avais déniché un plugin qui bloquait le copier/coller de l’internaute, tant qu’il était en consultation sur ton site. Je ne l’ai pas retrouvé, j’avais fait l’objet d’un piratage, même les liens sur certains mots avaient été dupliqués.
Je complète mon message :
Empêcher la sélection de texte à l’aide d’un plugin
Vous devez d’abord installer et activer le plugin WP Content Copy Protector. Après l’activation, le plugin fonctionne immédiatement. Les utilisateurs ne peuvent plus copier et coller du texte depuis votre site.
Bonjour, Je me demandais si un article “invité” avec le nom de l’auteur mentionné, pouvait être considéré comme du contenu dupliqué ?
Je vous remercie pour votre réponse
Catherine
Bonjour, pourquoi l’article serait-il dupliqué ?
Bonjour,
Relisant votre article notamment la partie sur la gestion des contenus dupliqués du fait d’étiquettes multiples, je trouve que vous éludez bien rapidement sans fournir de vraies réponses, à votre question pourtant tout à fait pertinente. Je vous cite :
“Comment empêcher la duplication des catégories ?
La solution idoine consiste à ne pas utiliser d’étiquettes. Si vous y tenez vraiment, réfléchissez bien, au vu des conséquences que cela peut engendrer. ”
Et…. pshiiit !
Je reste un peu sur ma faim.
J’aimerai bien une réponse un peu plus robuste et éprouvée de la part de spécialistes… 😉
Bonjour, quelle est ta question par rapport à ceci du coup ?
Je profite de mon nouveau passage sur le site, au détour d’une recherche sur le cas particulier du contenu dupliqué sur WordPress, pour vous féliciter pour ce super article et, plus globalement, le travail général réalisé sur WP Marmite. Une référence qui m’a inspirée à plusieurs reprises, dont la dernière en date pour rédiger mon article sur la bonne utilisation des étiquettes. Continuez comme ça ! Merci.
Merci beaucoup pour ton commentaire Benjamin ! Je suis ravi d’entendre que nos articles t’ont inspiré et aidé dans tes propres projets.
À bientôt sur WPMarmite ! 😊
Bonjour, j’ai lu avec intérêt votre article. J’ai plusieurs sites sur wordpress et mon webmaster m’a fait faux bon . En travaillant avec le logiciel Screemingfrog, j’ai vu que j’avais mes articles de blog qui étaient dupliqués automatiquement url de la page + page/
2/?et_blog
3/?et_blog
4/?et_blog jusqu’ à 8
Alors bien sur elles sont non indexées : on les a bloqué mais je trouve cela quand même embêtant. Car j’ai peur que cela impacte mon SEO et le temps passé sur mon site par les robots des moteurs de recherche. N’ y a t il pas une solution pour éviter à l’avenir ce genre de problème ?
En vous remerciant par avance
Bonjour et merci pour votre message !
Vous avez raison, même si ces pages sont actuellement non indexées, le simple fait qu’elles existent et soient crawlables peut gaspiller le « budget crawl » de Googlebot et compliquer la gestion de votre SEO à long terme.
Ce type de duplication que vous remontez est souvent lié à la pagination générée par certains constructeurs de pages ou thèmes WordPress (ici, cela ressemble à l’usage du module « blog » de Divi, qui génère ces URLs paginées du style /page/2/?et_blog). Même si vous les avez bloquées via robots.txt ou des balises « noindex », la meilleure solution reste en général d’éviter leur génération ou leur accessibilité quand c’est possible.
Voici quelques conseils pour aller plus loin :
1- Limiter la génération de pagination excessive : Si vous n’avez pas besoin de paginer vos articles de blog (ou si vous pouvez afficher plus d’articles par page), réduisez la pagination dans les réglages de votre thème ou module de blog.
2- Rediriger les pages paginées non désirées : Vous pouvez utiliser une extension comme « Redirection » pour rediriger automatiquement les URLs indésirables vers la page principale du blog ou un contenu pertinent.
3- Utiliser la balise canonique : Assurez-vous qu’une URL canonique pointe vers la page principale du blog pour toutes les pages paginées. Yoast SEO gère souvent cela automatiquement, mais ça vaut le coup de vérifier !
4- Limiter l’accès via robots.txt : Vous l’avez déjà fait, mais attention à ne pas bloquer l’accès à trop de ressources utiles pour Google !
5- Vérifier les options du thème ou du constructeur de page : Parfois, il y a des réglages pour désactiver la génération de ces URLs ou mieux les gérer.
Enfin, si ce problème vient bien d’un module spécifique (comme Divi ou un autre plugin de blog), il peut valoir le coup de consulter leur documentation ou leur support pour voir s’il existe une solution propre pour limiter ou supprimer ces paginations inutiles.
Bon courage dans la gestion de vos sites, et n’hésitez pas si vous avez d’autres questions ! 😊